


The Revolving Door of BI
When we upgrade our BI tools to address the same underlying challenges, it’s no surprise that the results don’t change—what we need is a fresh approach.

BI tools come with incredibly high switching costs. Implementations often involve layers of custom business logic, the migration of reports that are deeply embedded in business processes, and extensive user training. It can take up to a year to transition to a new platform successfully.
Despite the high up-front investment, companies continue to swap out their BI tools every 2-3 years. Is the ROI of switching from Tableau to PowerBI high enough to justify the cost? I’m not so sure.
The new features might be slightly different but the core functionality is pretty much the same, akin to a comparison of HubSpot vs Salesforce - but you don’t see companies switching CRMs every few years. What makes BI so different?
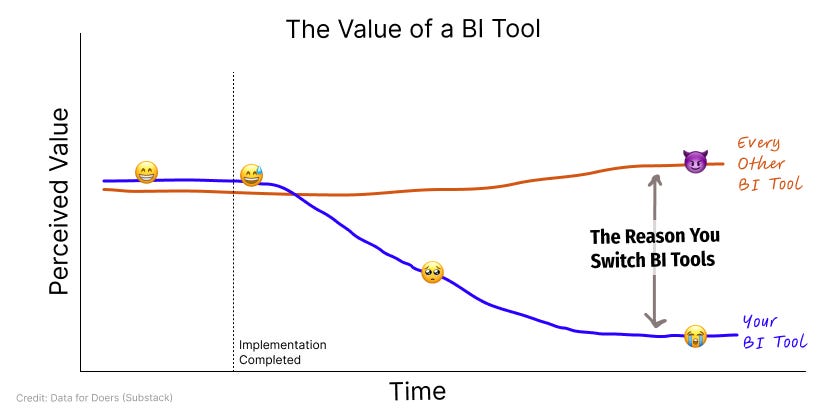
My observation: It’s not necessarily that new BI tools are dramatically superior; rather, the platforms we have fail to scale effectively as the organization evolves. Over time, the initial value delivered at implementation tends to degrade. As the underlying data models grow in complexity - these systems become slow, error-prone, and increasingly difficult for data teams to manage, leading to a perception that newer tools, despite only marginal improvements, offer a greener pasture.
So, what will it take to deliver a solution that endures?
In this post, I’ll explore the technical and organizational factors that contribute to this revolving door of BI solutions and share my thoughts on what needs to change for new BI solutions to achieve long-term success.
The Honeymoon Period of Every BI Implementation
Over the last decade, I’ve worked with more BI tools than I can count: Tableau, Chartio, Looker, Power BI, Superset, Metabase - the list goes on. Depending on your team and company size, these tools can cost upwards of $60k a year. Beyond the financial commitment, the implementation and maintenance of these systems require substantial resources. The setup is complex, involving custom logic and extensive training for business users, but the initial implementation is usually well-received. These tools provide clear visibility into metrics and meet the initial reporting needs of the business.
This is the honeymoon period of BI. Companies have clarity on what they need to measure, and data teams build pristine, well-curated tables that allow decision-makers to access and understand their metrics. This initial phase brings significant value as having comprehensive metrics at your fingertips is a huge win—good job, data team! 👏🏻
However, as questions evolve and new metrics, dimensions, and filters are needed, the existing data models powering the BI tool quickly become inadequate. Over time, the questions become more sophisticated, requiring more specific data insights that weren’t anticipated during the initial setup.
At an organizational level, this is a win. Not only are teams asking more questions, but they’re also asking better questions. They can ask follow-up questions based on what they’re seeing in the data, digging deeper to uncover new insights that can be applied to daily decision-making.
On a technical level - this presents a problem. It’s not easy to evolve the underlying data models. Especially as users are trying to do more “self-serve analytics” with their reporting tools, they’ll ask for one-off dimensions to be added to a dashboard (e.g., “A flag for customers who have purchased the same product twice within 48 hours” or “Last-touch attributed channel, but excluding email”). The data models quickly become a tangled mess of limited-purpose logic to incorporate new dimensions, filters, metrics, and data sources.
Complexity and Tech Debt
And it’s not just the ad-hoc questions that clutter the underlying data tables. We can’t forget about the strategic evolutions that require updated metric definitions and migrations to new data sources. The struggle becomes real to maintain continuity in existing reports while incorporating new logic. The nature of the beast is that all companies are constantly evolving, meaning their data structures grow in complexity, leading to increased maintenance times, slower performance, and more errors.
I worked on the data team at WeWork during a period of extremely high growth (1,200 ppl → 13,000 ppl in less than 2 years). There are many stories here that I’ll save for another day, but the fact of the matter is that our data architecture was put to the test, just like any hyper-growth company— and we learned a lot as a result. During this time, I’ll share two significant data model evolutions that caused major disruptions. We shifted our metrics from using the unit of “desks” to “memberships”, which required a complete overhaul of our data structures. This was in response to the company’s strategic shift to sell digital memberships, limited all-access memberships, and enterprise floor plans instead of just desks. You can imagine how this change would impact almost all parts of our reporting. Everything from customer counts to occupancy calculations needed to be changed.
At the same time, we migrated from Mixpanel to Heap for front-end tracking. While this migration might seem straightforward compared to the desk metrics overhaul, it was far from simple. Differences in identity resolution across devices, differences in the types of events and the corresponding properties tracked in each tool meant that this migration took over a year and caused substantial delays in data accessibility.
On the whole, these complexities lead to frustration for the business teams who rely on their BI tools for decision-making. As complexity grows, the systems become slower, errors become more frequent, and it takes much longer to integrate new data sources or metrics.
What’s worse is that the data team, who was the superstar a year ago when they “democratized data access” to the rest of the organization is now the “bottleneck to data-driven decision making”.
The Blame Game
Since data modeling issues are relatively invisible to the business, it’s nearly impossible to convince business teams to prioritize improvements until the system starts breaking down. Many engineers can relate if they’ve ever tried to advocate for refactoring their code. It’s an invisible problem, that no one cares about until they need to care. And if you’re at the point where you need to care, then you’re already in hot water.
In the context of data, problems often manifest at the BI layer, even though the root cause lies deeper in the stack. This is where the business feels the impact.
As data teams come under pressure to address the problems, there’s a natural tendency to focus on the BI platform. Replace the BI tool, solve the problem. It’s a win-win for data teams. Not only can they avoid the assumption of responsibility, but a migration to a new BI tool also presents an opportunity to refactor some of the messy data models as part of the effort to implement a new BI platform — a clean slate. There’s opportunity to deprecate legacy metrics (like “total desks” in the WeWork example), and start fresh with up-to-date requirements and cleaned up data models to match.
The problem is solved for the short term, the data team is the hero, and the cycle begins all over again.
Looking Ahead
Moving Towards Sustainable Solutions
It's important to recognize the pattern of frequent BI tool switching and understand that the real issue often lies in the complexity of evolving data models. The motivation to switch isn’t necessarily driven by a desire for the latest technology. Instead, it often stems from a desperate attempt to escape the complexity that has emerged from an unscalable architecture.
To build an enduring solution, we need to focus on tools that can flexibly accommodate an evolving data model. There are a few companies that have prioritized this as part of their product like Omni, Preql, and Narrator1. These tools are designed to easily extend the existing data model to add new features and dimensions on the fly without adding complexity to the underlying data model, ultimately addressing the core problem rather than just the symptoms.
AI: A New Face to a Familiar Problem
I’m concerned that newer solutions like text-to-SQL “AI/BI” tools might fall into the same trap as traditional BI tools. These solutions provide a new interface for interacting with data, but unless they address the underlying complexity of the data model, they risk becoming another face to a familiar problem. The core challenge remains: evolving data models and maintaining data quality as business needs change.
To succeed, these tools need to find ways to balance governance with flexibility. It’s widely accepted that clean and well-governed data sets are a prerequisite for earning trust and buy-in from the business. I’m skeptical that an LLM on top of the wild-west of a messy data warehouse can deliver the reliable results users need. Alternatively, an LLM querying a well-governed data model will face the same challenges as traditional BI tools. We will still need a flexible way to interact with and evolve our data models over time.
More Data, More Problems
Unfortunately, as data volumes grow and data centralization becomes easier than ever, these problems have accelerated. Now, every startup can set up its own centralized analytics warehouse, syncing data from various source systems (e.g., Stripe, Salesforce, Segment, … ), and adding or switching SaaS tools as needed. Companies are starting earlier and tracking more data than ever, but we still lack a scalable, sustainable solution to manage the evolving data structures and generate long-term value from our data platforms. It’s time to rethink how we architect our data models and break free of this infinite loop.
This is necessary. If for no other reason as "changing BI every 2-3 years" won't be viable when it's not just BI, it's your company's AI (in terms of context and comprehension).
Imagine telling the board you're overhauling the data stack and will lose 3 years of organizational memory because the data model became too complex 🤭
I wonder if the data model for WeWork could have been flexible enough to allow seamless transition from “desks” to “memberships”